Weighted average rank in Pandas
Posted on June, 2021 at 12:00 PM
In this tutorial we'll be looking at average weighted ranks in Pythons Pandas package. Find the code below in my github repo.
Installs
For this Tutorial, we just be using Pandas. Pandas is not install by default, so you must install via pip:
pip install pandas
Simple weighted average
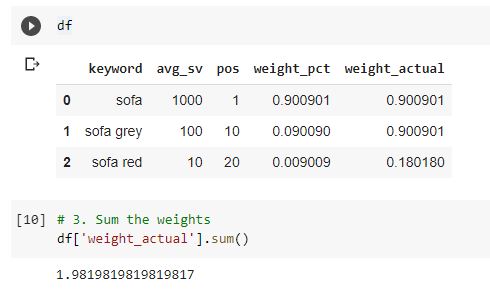
For the purpose of the example, I will create a simple DataFrame with some keywords their search volume and their ranking position (this is fictious data but you could imagine how a domain might rank for these keywords in varying positions). The weighted average will be based upon the position.
To get the weighted average, we have to do three steps.
- Determine the weight percetange
- Multiply the value by the weight percentage
- Sum the weighted values
df = pd.DataFrame({'keyword':['sofa', 'sofa grey', 'sofa red'], 'avg_sv':[1000,100,10], 'pos':[1, 10, 20]})
df['weight_pct'] = df['avg_sv'] / df['avg_sv'].sum()
df['weight_actual'] = df['pos'] * df['weight_pct']
Now we have the weighted value, all we need to do is sum the column and we will have the weighted average rank.
df['weight_actual'].sum()
Additionally you could refactor the steps into a function which you run on the DataFrame:
def add_weight_column(pos, weight):
weight_pct = weight / df['avg_sv'].sum()
weight_actual = weight_pct * pos
return [weight_pct, weight_actual]
for index, row in df.iterrows():
pos = row['pos']
weight = row['avg_sv']
weight_pct, weight_actual = add_weight_column(pos, weight)
df.loc[index,'weight_pct'] = weight_pct
df.loc[index,'weight_actual'] = weight_actual
df.weight_actual.sum()
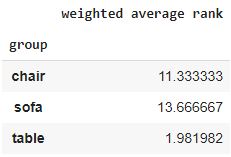
Groupby using weighted average
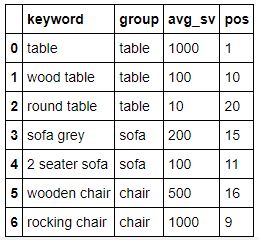
The next weighted average is used with a groupby - i.e. we can get the weighted average rank for a specific group. For this I have created a similar DataFrame, but added a category for the keywords.
df = pd.DataFrame({'keyword':['table', 'wood table', 'round table', 'sofa grey', '2 seater sofa', 'wooden chair', 'rocking chair'], 'group':['table', 'table','table', 'sofa', 'sofa', 'chair', 'chair'], 'avg_sv':[1000,100,10, 200, 100, 500, 1000], 'pos':[1, 10, 20, 15, 11, 16, 9]})
We use typical Pandas groupby syntax, but we will apply a custom function passing in the position and weighting value (which is average search volume), like so:
def wavg(group, avg_name, weight_name):
d = group[avg_name]
w = group[weight_name]
try:
return (d * w).sum() / w.sum()
except ZeroDivisionError:
return d.mean()
df.groupby('group').apply(wavg, 'pos', 'avg_sv').to_frame().rename(columns={0:'weighted average rank'})
The result is a DataFrame with all the weighted average positions over the group or product type in this instance.