Scraping sites using AJAX with Selenium
Posted on October 26, 2020 at 12:00 PM
Previously I have written about scraping sites using Python packages like Requests and Beautiful Soup, but what if the site is using AJAX to load content on the client side? These packages access the source code from the server but cannot view the updated source code when the page has been rendered in a web browser (and the associated JavaScript files have run). This is where you need to use a package like Selenium which can emulate a user navigating webpages in a browser.
Set up
For the purpose of this tutorial, we are not going to scrape any live websites, but put together some simple HTML and JavaScript files ourselves and run on a local server (using an extension in our code editor). The webapge will simply contain a button which, when clicked, fetches some external data from an API and adds new content to the page (this will be our AJAX). At this point, we'll create a Python script and use Selenium to navigate to our webpage, click the button and scrape the content which has been loaded in via AJAX.
Writing our HTML & JS files
HTML file
Our HTML file will be very simply and only contain a button, a container div for appending AJAX'ed content and a script tag linking to our JavaScript file. I have called this file index.html
JavaScript file
I have named the JavaScript file main.js and linked to it from the HTML file (as above). If you are not familar with Javascript do not worry about the code - in short, it listens to when the button is clicked, makes a request to a theRandom User Generator API, and then adds this user information to the DOM.
const btn = document.querySelector('.btn');
const cont = document.querySelector('.ajax-cont');
btn.addEventListener('click', (e) => {
fetch('https://randomuser.me/api/?results=10')
.then(res => res.json())
.then(data => {
let ui = document.createElement('ul');
cont.appendChild(ui);
let usersArr = data['results']
usersArr.forEach(user => {
let li = document.createElement('li');
li.textContent = `${user['name']['title']} ${user['name']['first']} ${user['name']['last']}`;
ui.appendChild(li);
})
});
});
With the HTML and JavaScript files complete, we now need to use a local server to host our webpage. I am using an extension in Visual Studio Code called 'live server' - more information can be found here. This extension should be available in the majority of other code editors like Atom, Sublime etc. Within VS code, you need to go to your extensions, search for 'live server' and install the extension. After restarting VS code you should be able to right click within the index.html and click 'Open with live server'. At this point our files will be hosted and viewable in the browser on https://127.0.0.1:5500/index.html. Viewing the page, and clicking the button should result in a list of random users as depicted below.

Python script
Installs
To get started we are going to need 2 packages: Selenium and Beautiful Soup. If you do not have these installed, you should go ahead and install them now using pip:
pip install selenium
pip install beautifulsoup4
With them installed, we can import them into the top of our script. Additionally we are going to import time (which comes pre installed with Python).
from selenium import webdriver
from bs4 import BeautifulSoup
import time
The last thing you will need to install is the Webdriver for Chrome. There are a couple of versions to choose from so you may need test which one works with your Chrome version. Once this file has downloaded, put the chromedriver in the folder in which you want to run your Python programme.
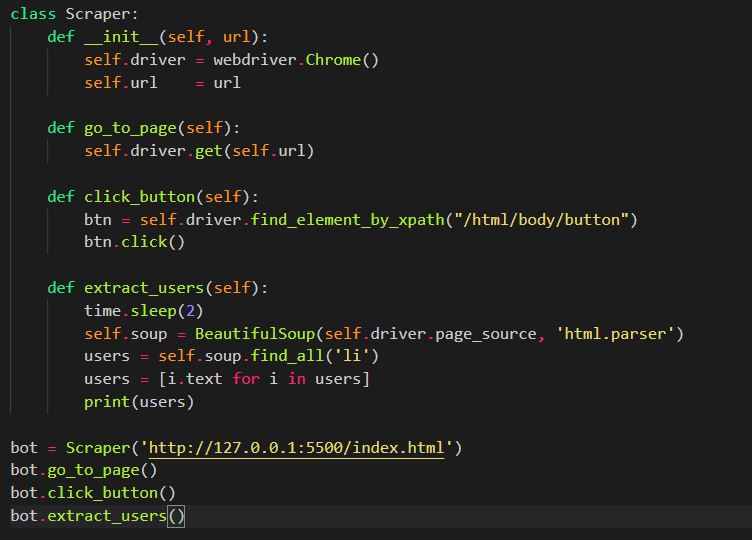
Creating the crawler class
For this project we are going to create a 'crawler' class which will contain methods directing the browser to take certain actions i.e. click a button, navigate to a page etc. We use the __init__ constructor which will create an instance of our class. The constructor function takes a URL which is our local host server running our HTML and JS files (https://127.0.0.1:5500/index.html). Within the constructor function we set the Selenium webdriver to local attribute.
We can now create the methods which will direct the webdriver to take certain actions:
- go_to_page() - this method simply tells the webdriver to navigate to a given page.
- click_button() - we find the button using its XPath and click the button.
- extract_users() - we sleep the program for 2 seconds and then parse the response from the page source into BeautifulSoup. We then use Beautiful Soups 'find_all' method to extract all the LI elements on the page. Finally, we do a quick bit of list comprehension to convert the LI soup tags into a list of strings and print the list of users to the terminal.
class Scraper:
def __init__(self, url):
self.driver = webdriver.Chrome()
self.url = url
def go_to_page(self):
self.driver.get(self.url)
def click_button(self):
btn = self.driver.find_element_by_xpath("/html/body/button")
btn.click()
def extract_users(self):
time.sleep(2)
self.soup = BeautifulSoup(self.driver.page_source, 'html.parser')
users = self.soup.find_all('li')
users = [i.text for i in users]
print(users)
With the class set up, we can now create a an instance of the class (passing it our locally hosted URL) and apply the methods to direct the browser to the page, click the button and get scrape the AJAX'ed users.
bot = Scraper('https://127.0.0.1:5500/index.html')
bot.go_to_page()
bot.click_button()
bot.extract_users() # prints(['Mr Ümit Akyüz', 'Mrs Oraldina Nascimento', 'Mr Logan Cooper', 'Mr Andres Vidal', 'Ms Aada Sippola', 'Mr Vilho Peltonen', 'Mr پارسا کریمی', 'Miss Maja Kristensen', 'Mr Jacob Cooper', 'Mr Floyd Holmes'])
And there we have it - we have been able to extract content from a webpage after the client has clicked a button and new content has been AJAX'ed on the page. Although this is a very simple example, Selenium can be used to do for web testing and can also be used to log into websites and do many other tasks.
Code takeaway
This code can be added to a python file (.py) and run in the terminal.
from selenium import webdriver
from bs4 import BeautifulSoup
import time
class Scraper:
def __init__(self, url):
self.driver = webdriver.Chrome()
self.url = url
def go_to_page(self):
self.driver.get(self.url)
def click_button(self):
btn = self.driver.find_element_by_xpath("/html/body/button")
btn.click()
def extract_users(self):
time.sleep(2)
self.soup = BeautifulSoup(self.driver.page_source, 'html.parser')
users = self.soup.find_all('li')
users = [i.text for i in users]
print(users)
bot = Scraper('https://127.0.0.1:5500/index.html')
bot.go_to_page()
bot.click_button()
bot.extract_users() # prints(['Mr Ümit Akyüz', 'Mrs Oraldina Nascimento', 'Mr Logan Cooper', 'Mr Andres Vidal', 'Ms Aada Sippola', 'Mr Vilho Peltonen', 'Mr پارسا کریمی', 'Miss Maja Kristensen', 'Mr Jacob Cooper', 'Mr Floyd Holmes'])