Building a basic web crawler with Requests, BeautifulSoup and SQLite
Posted on 03 May 2019 at 15:45 PM
In this tutorial will be creating a basic web crawler which extracts the title, description, canonical, number of links and page contents and stores in an SQLite database. All this data will be stored with a date which means you can track site changes over time. In the future I'll be writing a script which checks if onpage elements have changed and subsequently sends an alert email to the webmaster.
- Installs
- Connecting to SQLite database and creating a table
- Functions to extract data from HTML source code
- Starting the web crawler
- Final thoughts
- Code takeaway
Installs
To build our web crawler we will be using a number of packages including: SQLite, Reqeusts, regex and BeautifulSoup. Both SQLite and Requests come pre-installed as standard with Python although BeautifulSoup will be need to be installed via pip using the command:
pip install beautifulsoup4
Before you can use any of the packages, you must first import them into the top of your Python script.
import sqlite3
import re
import requests
from bs4 import BeautifulSoup
Connecting to SQLite database and creating a table
If you have not used SQLite package before i'd reccomend you take a quick glance at my SQLite basics with Python tutorial. Also it's worth pointing out if you want to have an interface as depicted in the heading image you'll need to download DB browser for SQLite.
Now to connect to the SQLite database. First we specify 'sqlite3.connect()' and pass the database name into the parameter (if the database does not exist it will be created with the given name). We then create a cursor object by calling the 'cursor()' method.
# connect to database
db = sqlite3.connect('site_crawl.db')
cursor = db.cursor()
The way we want to structure the database is to have lots of individual tables referring to different domains that we have crawled. To do this, we'll ask for a user to enter the starting URL to crawl and then make a table based upon the URL. If the URL / table is already in the database, the web crawler will add to the existing table. If not, it will create a new table. Note, I have written a quick and dirty function to extract the name from the URL i.e. remove the https:// and .com.
# get the URL to crawl
url = input("URL to crawl: ")
if len(url) < 1:
url = "https://charlieojackson.co.uk"
def get_db_name(url):
"""Takes a URL and strips it to use as a table name"""
if 'www' in url:
url_clense = re.findall('ht.*://www\.(.*?)\.',url)
url_clense = url_clense[0].capitalize()
return url_clense
else:
url_clense = re.findall('ht.*://(.*?)\.',url)
url_clense = url_clense[0].capitalize()
return url_clense
db_name = get_db_name(url)
# Create database
cursor.execute("CREATE TABLE IF NOT EXISTS " + db_name + " (URLID INTEGER PRIMARY KEY AUTOINCREMENT,URL varchar(255),Title varchar(255),Description varchar(255),InternalLinks INTEGER,ExternalLinks INTEGER, PageContents TEXT, Canonical varchar(255), Time TIMESTAMP DEFAULT CURRENT_TIMESTAMP)")
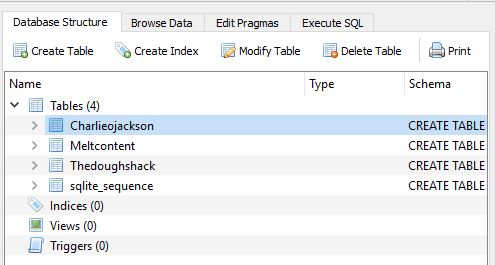
Note when we create the table we provide all the relevant columns and their data types which we will be adding in as we crawl a website. The 'IF NOT EXISTS' clause means new domains will create a new table, whereas existing crawled domains will be added to the appropriate table. See the image below as an example.
Lastly, we append the given URL to a list - the list is where we will store all the URL's that need to be crawled - more on that shortly.
all_urls = []
all_urls.append(url)
Functions to extract data from HTML source code
Now we have our database set up and ready, we can think about adding some data to it. We are going to write three functions; 1 which extracts the content from the page (like the title, description, canonical tag etc), 1 which extracts links and 1 that inserts the data into our SQLite database.
Extracting content
Our function will take one parameter which will essentially be the HTML from the webpage. However, we'll convert this HTML into Beautiful Soup before passing into our function. Beautiful Soup takes raw HTML and fixes all the little errors in the HTML code and creates a 'parse tree' which allows you to find HTML elements with ease. This means we can take the 'soup' and use attributes like 'title' to pull the page title from the HTML source code. In addition, we can find all the relevant tags using the 'find' method. We use a try/except here so if we are unable to find certain elements, we set the variable equal to 'Null'. Lastly, we return the data extracted from the soup.
def extract_content(soup):
"""Extract required data for crawled page"""
title = soup.title.string
try:
description = soup.find("meta", {"name":"description"})['content']
except:
description = 'Null'
try:
canonical = soup.find('link', {'rel':'canonical'})['href']
except:
canonical = "Null"
contents_dirty = soup.text
contents = contents_dirty.replace("\n","")
return (title, description, contents, canonical)
Extracting links
As with our previous function to extract content, to extract links we also pass in the 'soup' to our function. We find all the links with the method 'find_all('a')' passing in 'a' as a parameter. We then loop through the links and run a couple conditionals - if the links starts with the inputted URL we know it is within the TLD, and then we also check if the link has been found previously in our list i.e we don't want to crawl the same URL multiple times. If it pass's both these conditionals we append it to our list named 'all_urls'. We also return the total number of links found on the page.
def extract_links(soup):
""""Extract links and link counts from page"""
links_dirty = soup.find_all('a')
for link in links_dirty:
if str(link.get('href')).startswith(url) == True and link.get('href') not in all_urls:
if '.jpg' in link.get('href') or '.png' in link.get('href'):
continue
else:
all_urls.append(link.get('href'))
return (len(links_dirty))
Inserting data into SQLite database
Our two pervious functions have extracted all the data we currently desire, know we'll write a function to insert this data into our database. The function takes one parameter which is a tuple of all the data we have gathered. We extract all the data passed in the function and insert into the database. Lastly we save our insert using the 'commit()' method.
def insert_data(extracted_data):
"""Insert the crawled data into the database"""
url,title, description, contents, no_of_links, canonical = extracted_data
cursor.execute("INSERT INTO " + db_name + " (URL, Title, Description, ExternalLinks, PageContents, Canonical) VALUES(?,?,?,?,?,?)",(url, title, description, no_of_links, contents, canonical,))
db.commit()
Starting the web crawler
Finally we can get the web crawler going. Remember we are storing all the URL's in our list named 'all_urls'. When we start the crawler, the list only has one URL - that's the URL we gave it at the beginning. We use a while loop and count - this is incremented every time a loop is completed. We use this count to slice the list (named 'all_urls') and make a request using the Request package. If the request returns a https code 200 we know we have got a valid page and we use our three functions to extract the content, extract the links and then insert the data. As noted, we then increment the count and do the same for the next URL. This loop runs until the counter is bigger than the length of the list i.e. there are no more URL's to crawl.
link_counter = 0
while link_counter < len(all_urls):
try:
print(str(link_counter) + " crawling: " + all_urls[link_counter])
r = requests.get(all_urls[link_counter])
if r.status_code == 200:
html = r.text
soup = BeautifulSoup(html, "html.parser")
no_of_links = extract_links(soup)
title, description, contents, canonical = extract_meta_data(soup)
insert_data((all_urls[link_counter], title, description, contents, no_of_links,canonical))
link_counter += 1
except Exception as e:
link_counter += 1
print(str(e))
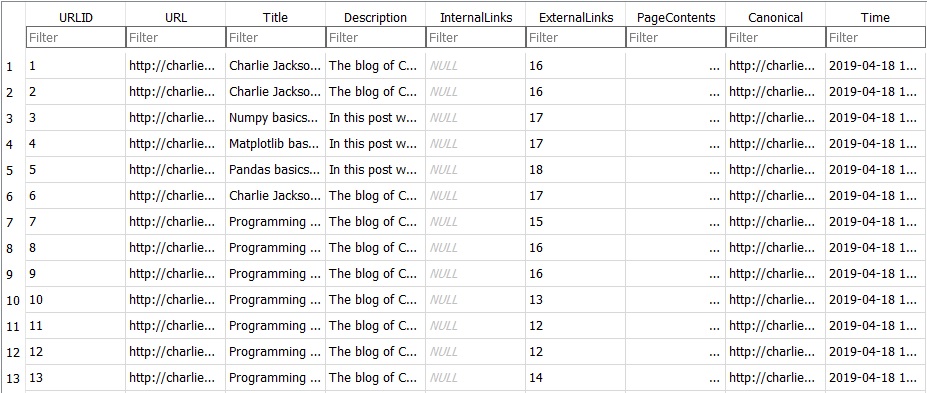
Once the crawler is done, in your local directory there will be a SQLite database - if you open this with the DB viewer as noted earlier, you will see a database similar to the image below.
Final thoughts
There are a couple things to consider here - firstly there are a moral considerations for web crawling/scraping in general. Webmasters won't want bots scraping content from their sites. They can also slow sites down or even crash sites when done aggressively - by this I mean trying to crawl hundreds or thousands of pages per seconds. Just to note, the crawler example above is very slow and will not cause any issues for sites. Web crawling does have its place though - for example if you need to find broken links on your site, or search engines are not indexing your site correctly you'll need to investigate what's going on. The main thing is to crawl sites slowly and be respectful - you can check out any sites robots.txt file by applying it the top level domain i.e. https://charlieojackson.co.uk/robots.txt. This file provides directions to web crawlers and should be respected. Search engines will always look at this file first before crawling a domain to see if the webmaster allows the site to be crawled.
Now onto the more technical side of things. One issue with the crawler is that as the list of URLs gets larger, the crawler will slow down. i.e. for each URL it finds it has to check in the list if it's already been found. For a small site like mine which has less than 100 pages at the time of writing, this is not an issue. But say your crawling booking.com which has over 50 million pages in Googles index and even more when you consider pages that are no indexed. For larger sites you'll need to consider speed and how to make the crawler faster. This could be changing how you store your data i.e. a list (using the built in method 'set()'') or a dictionary or in SQL. You could also put the crawler onto a server with more computing power or thread the script so it crawls multiple pages at once. There isn't a clear-cut answer here, and its likely a combination of things which I'll test in upcoming posts.
Code takeaway
The following code can be used in a python file and run in the terminal.
# This script is used to crawl a site, and store some information including the meta title, meta description, canonical, no of internal links and no of external links
# This script is used to crawl a site, and store some information including the meta title, meta description, canonical, no of internal links and no of external links
import sqlite3
import re
import requests
from bs4 import BeautifulSoup
import time
start = time.time()
# connect to database
db = sqlite3.connect('site_crawl.db')
cursor = db.cursor()
# get the URL to crawl
url = input("URL to crawl: ")
if len(url) < 1:
url = "https://charlieojackson.co.uk"
def get_db_name(url):
"""Takes a URL and strips it to use as a table name"""
if 'www' in url:
url_clense = re.findall('ht.*://www\.(.*?)\.',url)
url_clense = url_clense[0].capitalize()
return url_clense
else:
url_clense = re.findall('ht.*://(.*?)\.',url)
url_clense = url_clense[0].capitalize()
return url_clense
db_name = get_db_name(url)
# Create database
cursor.execute("CREATE TABLE IF NOT EXISTS " + db_name + " (URLID INTEGER PRIMARY KEY AUTOINCREMENT,URL varchar(255),Title varchar(255),Description varchar(255),InternalLinks INTEGER,ExternalLinks INTEGER, PageContents TEXT, Canonical varchar(255), Time TIMESTAMP DEFAULT CURRENT_TIMESTAMP)")
all_urls = []
all_urls.append(url)
def extract_content(soup):
"""Extract required data for crawled page"""
title = soup.title.string
try:
description = soup.find("meta", {"name":"description"})['content']
except:
description = 'Null'
try:
canonical = soup.find('link', {'rel':'canonical'})['href']
except:
canonical = "Null"
contents_dirty = soup.text
contents = contents_dirty.replace("\n","")
return (title, description, contents, canonical)
def extract_links(soup):
""""Extract links and link counts from page"""
links_dirty = soup.find_all('a')
for link in links_dirty:
if str(link.get('href')).startswith(url) == True and link.get('href') not in all_urls:
if '.jpg' in link.get('href') or '.png' in link.get('href'):
continue
else:
all_urls.append(link.get('href'))
return (len(links_dirty))
def insert_data(extracted_data):
"""Insert the crawled data into the database"""
url,title, description, contents, no_of_links, canonical = extracted_data
#print(title,"\n", description,"\n", contents,"\n",no_of_links,"\n", deduped_links)
cursor.execute("INSERT INTO " + db_name + " (URL, Title, Description, ExternalLinks, PageContents, Canonical) VALUES(?,?,?,?,?,?)",(url, title, description, no_of_links, contents, canonical,))
db.commit()
link_counter = 0
while link_counter < len(all_urls):
try:
print(str(link_counter) + " crawling: " + all_urls[link_counter])
r = requests.get(all_urls[link_counter])
if r.status_code == 200:
html = r.text
soup = BeautifulSoup(html, "html.parser")
no_of_links = extract_links(soup)
title, description, contents, canonical = extract_content(soup)
insert_data((all_urls[link_counter], title, description, contents, no_of_links,canonical))
link_counter += 1
except Exception as e:
link_counter += 1
print(str(e))
cursor.close()
db.close()
end = time.time()
print(end - start)