Predicting football player positions using k-Nearest Neighbors
Posted on October 25, 2020 at 12:00 PM

In this tutorial, we will use the FIFA data set (from 2020) containing records of ~18k players to predict positions for new players. For simplicity, we will either predict a player to be a midfielder or a defender. The data set from FIFA contains players with their respective positions as well as scores out of 100 for certain skills like passing, dribbling, shooting etc. Thus, we have a labeled data set which we can use to make predictions on new players. In this tutorial we will be using the k-Nearest Neighbors algorithm.
- Data set
- Installs / required packages
- k-Nearest Neighbour algorithm
- Classifying football players
- Prediction positions for new players
- Code takeaway
Data set
We will be using the FIFA 2020 player data - the data set can be downloaded from kaggle: https://www.kaggle.com/stefanoleone992/fifa-20-complete-player-dataset
Installs
We will be using 3 packages - if you do not already have them installed you can go ahead and install them now using pip:
pip install pandas
pip install scikit-learn
pip install numpy
Once installed, we will import Pandas & Numpy (with their usual aliases) as well as the k-Nearest Neighbor algorithm. Additionally, we'll use another function which will help in splitting our data into training and testing sets.
import pandas as pd
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
k-Nearest Neighbors algorithm
K-Nearest Neighbors is a clustering algorithm used to classify new data based upon its 'closeness' to other laballed data points. As it uses labeled data to make predictions on new data, it is a supervised learning technique. The features for k-Nearest Neighbor algorithm must be continous rather than categorical.
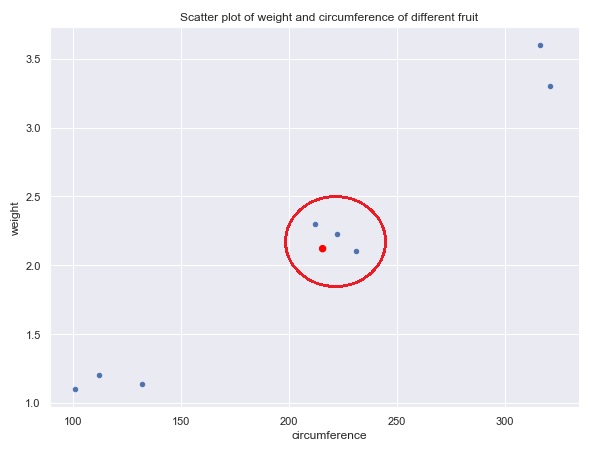
Say we have a colletion of labeled data about different fruits. The fruits in our data set are either limes, oranges or melons - these are our labels / categories. For each peice of fruit we have two features: the circumference and weight. We can now plot all weights and circumferences of each fruit on a scatter plot (depicted below). Now, say we had a new piece of fruit added to the dataset with its size and cirumference but without a label / category (the red dot on the graph below). Based upon its nearest neighbors (fruits with similar weight / circumference) we could take a good guess at what that fruit is. The k-Nearest Neighbor algorithm allows you to specify how how many neighbors to take into account. Looking at the graph below, we have taken three neighbors (captured inside the red circle) into account and based upon the most frequent neighbors you can guess the model can predict what piece of fruit it likely is - in this case it is an orange.
Classifying football players
As noted earlier, we will be using the FIFA 2020 player data set and will look to simply categorise players as either a 'midfielder' or 'defender' based upon their skill sets like passing ability, dribbling ability etc.
First of all we will read in the data using Pandas 'read_csv()' function. Then we remove goalkeepers from the dataset. Finally we will create a new column in the DataFrame to categorise the different positions as either 'midfielder' or 'defender'. Currently the positions are more granular and include 'RW' (right wing), 'ST' (striker), 'RB' (right back) to name a few. For this we will write a quick and dirty lambda function.
df = pd.read_csv('players_20.csv')
df = df[df['player_positions'] != 'GK'] # remove goal keeper from dataset
df['position'] = df['player_positions'].apply(lambda x: 'defense' if 'B' in x else 'midfield')
Now we have our label / category we can now look at different features that can inform our category. There are a number of features in this data set which we can choose from, but for simplicity we will look at 4 columns to use as features: shooting, passing, dribbling, defending. We must take these features and convert them into a Numpy array (by calling the '.value' attribute on the DataFrame) so they can be fed into the algorithm - we will store this in our X variable. Similarly, we must take the label / category as an Numpy array - we will store this in a variable named y. With the features and labels now defined and stored in variables we can pass these into our training function (provided by sklearn). Additionally we specify the size of the test as a percentage of total and set stratefy to 'y'. This function splits out our data set and returns tuple containing the X training set and test set as well as the y training and test sets.
df = df[['position', 'shooting','passing','dribbling','defending']]
X = df.drop('position', axis=1).values
y = df['position'].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.4, stratify=y)
With the data split out we can finally instantiate the k-Nearest Neighbor algorithm and specify how many neighbors we want to use (in this case 5, although you can try changing this number and testing how well the algorithm performs). We pass the testing data to the algorthm and fit the data. Lastly we can use the test data (which is already labeled) to see how accurate the algorithm was at predicting the correct label.
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)
print(knn.score(X_test, y_test)) # prints 0.87 - i.e. 87% accurate
Note, the model was able to predict the labels of the test data correctly 87%. 13% it predicted a players position incorrectly. Obviously we would like to the model to be as accurate as possible, and there are additional ways we could do this, but for the purpose of this tutorial we will accept 87% accuracy.
Predicting positions for new players
With the model now trained, we can pass in new player features and get a label/category (either defender of midfielderer) for the player. We will take a couple of retired football players from 2016 - Steven Gerrard (a midfielder) and Nemanja Vidic (a defender), to test our model and predict their position. These players features (shooting, passing, dribbling and defending scores) have been taken from previous FIFA records and provided in a Numpy array below and stored in variables. Now all we need to do is call the predict method on our model, pass in our player features and our model will return a prediction!
n_vidic = np.array([[39,55,51,84]])
s_gerrard= np.array([[83,85,75,70]])
print(knn.predict(s_gerrard)) # prints ['midfield']
print(knn.predict(n_vidic)) # prints ['defence']
And there you have it, our model was able to correctly predict that Steven Gerrard is a midfielder and Nemanja Vidic a defender.
Code takeaway
This code can be added to a python file (.py) and run in the terminal.
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
import numpy as np
df = pd.read_csv('players_20.csv')
df = df[df['player_positions'] != 'GK']
df['position'] = df['player_positions'].apply(lambda x: 'defence' if 'B' in x else 'midfield')
df = df[['position', 'shooting','passing','dribbling','defending']]
# create features and labels
X = df.drop('position', axis=1).values
y = df['position'].values
# split into training and testing set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.4, stratify=y)
# instantiate model and fit the model to training set
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)
# print the accuracy score
print(knn.score(X_test, y_test))
# predict new players
n_vidic = np.array([[39,55,51,84]])
s_gerrard= np.array([[83,85,75,70]])
print(knn.predict(s_gerrard))
print(knn.predict(n_vidic))