Keyword research with Google Suggest API
Posted on October 8th, 2022 at 12:00 PM
In this post we do keyword research using the Google Suggest API - and look at a recursive approach for endless keywords.
You’ve likely seen the screen grab above - it's a feature at the bottom of Google's search listing pages. It shows you related searches that you might be interested in based upon your current search. Google knows how one search relates to another; they look at the chain of searches made i.e. a user searching for ‘football’ occasionally goes on to make another search for ‘football live’ and Google search pages provide this as a feature to help steer users to their desired search result.
This is valuable keyword data as it lets us marketers know what users are searching for and related terms / topics for a given keyword. This in turn can help inform optimisation and content ideas.
A number of tools already make use of this data - ‘AnswerThePublic’, being one of them, is perhaps the most known tool. It allows you to enter a keyword and find related questions. A lot of this data is from the related searches in Google which is available via their API. In the Python code below, we look at how you can get keyword data similar to AnswerThePublic via Google suggest API.
Getting started
We are going to make a request to the API, parse the response and store it in a Python list. We will then convert the list into a Python DataFrame. With that said, we need to import some packages:
import requests
import pandas as pd
import numpy as np
If you do not have these packages installed you will need to install via pip:
pip install request, pandas, numpy
Querying the Google Suggest API
We will create a function that accepts a keyword. We then do list comprehension to merge our keyword with a list of interrogative words. We then iterate over our list, querying the API with our keyword and storing the output from the API in a list. Note, within the 'API_URI' we set the 'gl' paremeter to 'uk' - you can change this to other countries as required such as 'us', 'fr', 'de' etc. Lastly we convert our list to a Pandas DataFrame:
def get_questions(keyword):
output_keywords = list()
questions_lst = ['who', 'what', 'are', 'when', 'how', 'is']
keywords_lst = [f"{keyword} {i}" for i in questions_lst]
for i in keywords_lst:
API_URI = f"https://suggestqueries.google.com/complete/search?&q={i}&gl=uk&client=chrome&_=1663410981189"
r = requests.get(API_URI)
keywords_res = r.json()[1]
for keyword_suggestion in keywords_res:
output_keywords.append([i, keyword_suggestion])
df = pd.DataFrame(output_keywords, columns=['seed_keyword', 'suggestion'])
return df
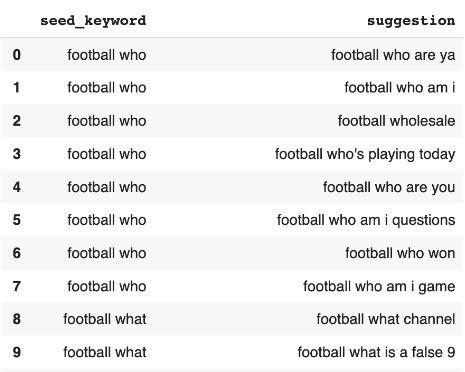
Calling our 'get questions' function as above with the parameter ‘football’ and printing the response, should look something like this (I am just showing a sample of 10 suggestions).
get_questions('football')
Using recursion for endless keywords
There once was a tool called ‘Keyword Shitter’, now migrated to ‘Keyword Sheeter’. The principle remains the same: you input one keyword, it pulls suggestions via the Google Suggest API, it then uses those keywords to query the Google Suggest API to get more suggestions, it then uses those keywords to query the Google Suggestion API to get more suggestions…. You get the picture, it’s never ending.
We will write a recursive function (a function that calls itself) to produce something similar to ‘Keyword Sheeter’.
First we will define some variables outside of the function:
RECURSION_DEPTH = 50
output_keywords = list()
flat_kw_lst = list()
recursion_count = 0
We will set a variable for the recursion depth - in this case I have set it to 50 which is where we will stop executing the function (you can make this larger or smaller as required). We’ll also create a couple of lists to store the outputs from the API, and a counter to store how many times we have called the function (to track the recursion depth).
Now for the function - it accepts a keyword and a path (when calling the function, set this to the same as the keyword - we are going to store how the suggestions are related to one another or the path to reaching the final keyword). We first check that the keyword is not in the ‘flat_kw_lst’ - this is to stop duplications. If we already have this keyword we simple return, else we add it to our list. The second if statement is to break out of the recursion once we reach the ‘RECURSION_DEPTH’. If we are not at the recursion depth, we can call the API, parse the response, add it to our lists to store and then call the function with the suggested keyword (this is the recursion - a function is calling itself). This will continue calling itself until it reaches the recursion depth (currently set at 50) and then bubble up and break out of the function.
def get_suggestions(keyword, og_path):
if keyword in flat_kw_lst:
return
else:
flat_kw_lst.append(keyword)
global recursion_count
recursion_count += 1
if recursion_count >= RECURSION_DEPTH:
return
API_URI = f"https://suggestqueries.google.com/complete/search?&q={keyword}&gl=uk&client=chrome&_=1663410981189"
r = requests.get(API_URI)
keywords_res = r.json()[1]
for keyword_suggestion in keywords_res:
new_path = og_path + f" > {keyword_suggestion}"
output_keywords.append([keyword, keyword_suggestion, recursion_count, new_path])
for keyword_suggestion in keywords_res:
new_path = og_path + f" > {keyword_suggestion}"
get_suggestions(keyword_suggestion, new_path)
We can call the function passing in a keyword, in this case ‘football’ and a path of ‘football’.
get_suggestions('football', 'football')
This function runs and stores keywords in our 'output_keyword_lst' - we now convert this list into a DataFrame, and print a sample of the DataFrame to get the below:
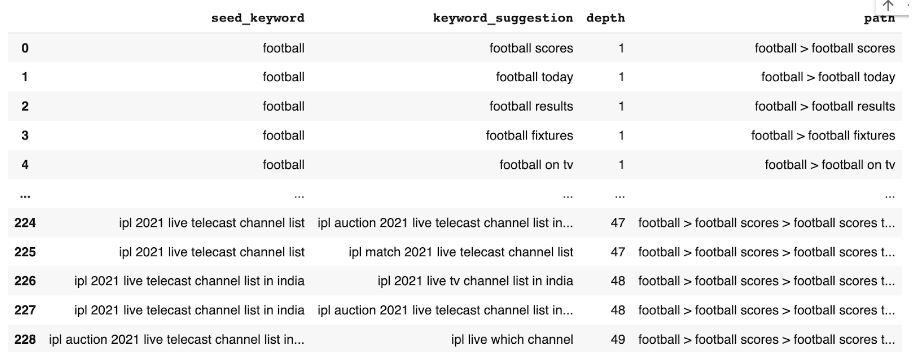
And there we have it - something similar to keyword shitter. Note, if you are going to be hitting the API a lot, you may want to slow the requests down by using Python's time module and sleeping for a few seconds before executing each function.
If you have found this interesting, or have additional ideas I'd love to hear from you - you can reach me via the contact form.