SEO, Python programming and web development
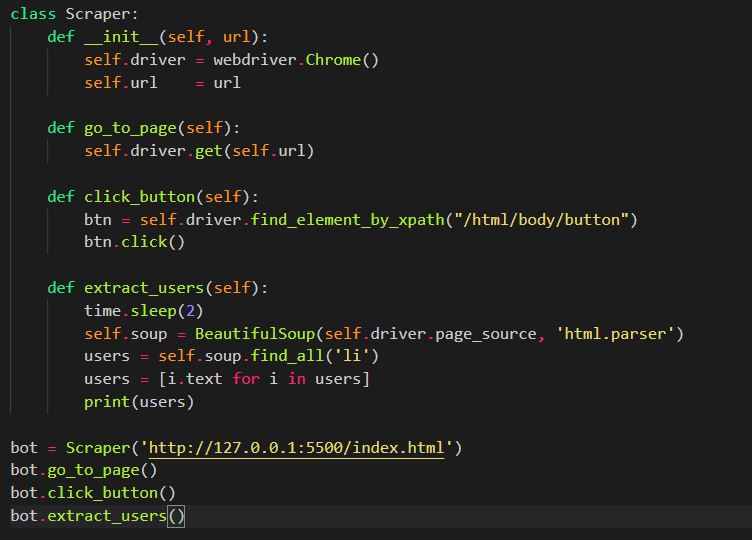
Scraping sites using AJAX with Selenium
In this post we look at crawling / scraping sites using AJAX with Selenium
Read More →
Predicting football player positions with k-Nearest Neighbors
In this post we look at the supervised machine learning model k-Nearest Neighbor
Read More →